Finding the Local Optimal Number of Hidden Nodes in a Neural Network
By Priscilla Jenq (pjj)
Checkpoint
Summary of Project
(As given in project proposal) For this project, I am interested in studying the application of artificial neural networks (ANNs) in the financial industry. Specifically, I am interested in building and analyzing an ANN to do stock market predictions. Furthermore, I’d like to find out the minimum number of nodes in the hidden layer that can achieve the best prediction in terms of accuracy. So the goal of this project is to answer the following question: how many nodes in a single hidden layer of an ANN will achieve this?
Work Completed
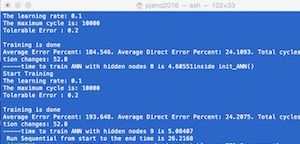
So far, I am on schedule and have a working sequential version of the artificial neural network (screenshot of program output shown below). In addition, I have also completed a working parallelized version with Open MP and have been able to run/test on the GHC machines. A challenge that I came across while implementing and running the parallel version was that I was continuously getting segmentation faults. Eventually, I resolved this error by moving the creation of the ANN from inside the parallel for loop to outside the loop so that it is done sequentially. In terms of what I've achieved so far, I was able to train the neural network using stock data (opening price, highest price, closing price, volume and adjusted closing price) given to it through a CSV file and predict the "direction" of the next day's open price (i.e. will it be higher or lower than current day?) with some error. Running the parallel version with 4, 8 or 16 threads, I observed a 5x speedup when compared to the purely sequential version. I will continue to do further iterations and investigate if a higher speedup can be achieved.
Goals + Deliverables
I believe that I will be able to produce all deliverables, one of which is to answer the question: what is the minimum number nodes of the hidden layer that is needed to achieve the best accuracy? As mentioned before, another goal that I have is to further investigate if the speedup can be increased. For the parallelism competition, I still plan to show graphs that illustrate the relationship between predicting accuracy and the number of hidden nodes when fixing the characteristics of the input and output layers. As a side product, I will also show the speed up factor of training of ANN when parallel machines are used in this experiment.
Revised Schedule
| Week |
Plan |
Status |
| 4/10 - 4/17 |
Design Solution |
Completed |
| 4/18 - 4/25 |
first iteration of implementation and testing, submit checkpoint report |
Completed sequential implementation and first version of parallel implementation |
| 4/26 - 5/5 |
Continue implementation, testing and analysis |
In progress |
| 5/3 - 5/5 |
Analysis of results |
In progress (while testing code) |
| 5/6 - 5/9 |
Complete project report and prepare slides/presentation material |
In progress/To do |
| 5/10 - 5/12 |
Polish everything for presentation day + buffer days |
To do |